
Node.js事件循环与多线程
nodejs事件循环与多进程
why
- 事件循环对于深入理解nodejs异步至关重要
- fs, net,http,events
- 事件循环是企业面试中的最高频考题之一
- 能驾驭nodejs多进程是一名资深前端工程师的标志
课程介绍
- 了解事件循环的概念
- 学习浏览器中的事件循环机制
- 学习nodejs中的事件循环机制
- 了解多进程,多线程之间的区别
- 学习nodejs中的多进程并使用cluster来开启多进程
学习目标
- 深入掌握浏览器与nodejs中的事件循环机制,并且能理解它们之间的区别
- 使用cluster开启多进程
第一章 事件循环介绍
浏览器中的事件循环
为了协调事件(event),用户交互(user interaction),脚本(script),渲染(rendering),网络(networking)等,用户代理(user agent)必须使用事件循环(event loops)。
To coordinate events, user interaction, scripts, rendering, networking, and so forth, user agents must use event loops as described in this section. Each agent has an associated event loop.
- 事件:PostMessage, MutationObserver等
- 用户交互: click, onScroll等
- 渲染: 解析dom,css等
- 脚本:js脚本执行
nodejs中的事件循环
事件循环允许Node.js执行非阻塞I / O操作 - 尽管JavaScript是单线程的 - 通过尽可能将操作卸载到系统内核。
由于大多数现代内核都是多线程的,因此它们可以处理在后台执行的多个操作。当其中一个操作完成时,内核会告诉Node.js,以便可以将相应的回调添加到轮询队列中以最终执行。
The event loop is what allows Node.js to perform non-blocking I/O operations — despite the fact that JavaScript is single-threaded — by offloading operations to the system kernel whenever possible.
Since most modern kernels are multi-threaded, they can handle multiple operations executing in the background. When one of these operations completes, the kernel tells Node.js so that the appropriate callback may be added to the poll queue to eventually be executed. We’ll explain this in further detail later in this topic.
- 事件: EventEmitter
- 非阻塞I / O:网络请求,文件读写等
- 脚本:js脚本执行
事件循环的本质
在浏览器或者nodejs环境中,运行时对js脚本的调度方式就叫做事件循环。
setTimeout(() => { |
第二章 浏览器事件循环
Javascript为什么是单线程的?
浏览器js的作用是操作DOM,这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
任务队列
单线程就意味着所有任务需要排队,如果因为任务cpu计算量大还好,但是I/O操作cpu是闲着的。所以js就设计成了一门异步的语言,不会做无畏的等待。任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
(3)一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
setTimeout(() => { |
主线程从”任务队列”中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
宏任务与微任务
除了广义的同步任务和异步任务,JavaScript 单线程中的任务可以细分为宏任务(macrotask)和微任务(microtask)。
macrotask: script(整体代码), setTimeout, setInterval, setImmediate, I/O, UI rendering。
microtask:process.nextTick, Promise, Object.observe, MutationObserver。
- 宏任务进入主线程,执行过程中会收集微任务加入微任务队列。
- 宏任务执行完成之后,立马执行微任务中的任务。微任务执行过程中将再次收集宏任务,并加入宏任务队列。
- 反复执行1,2步骤
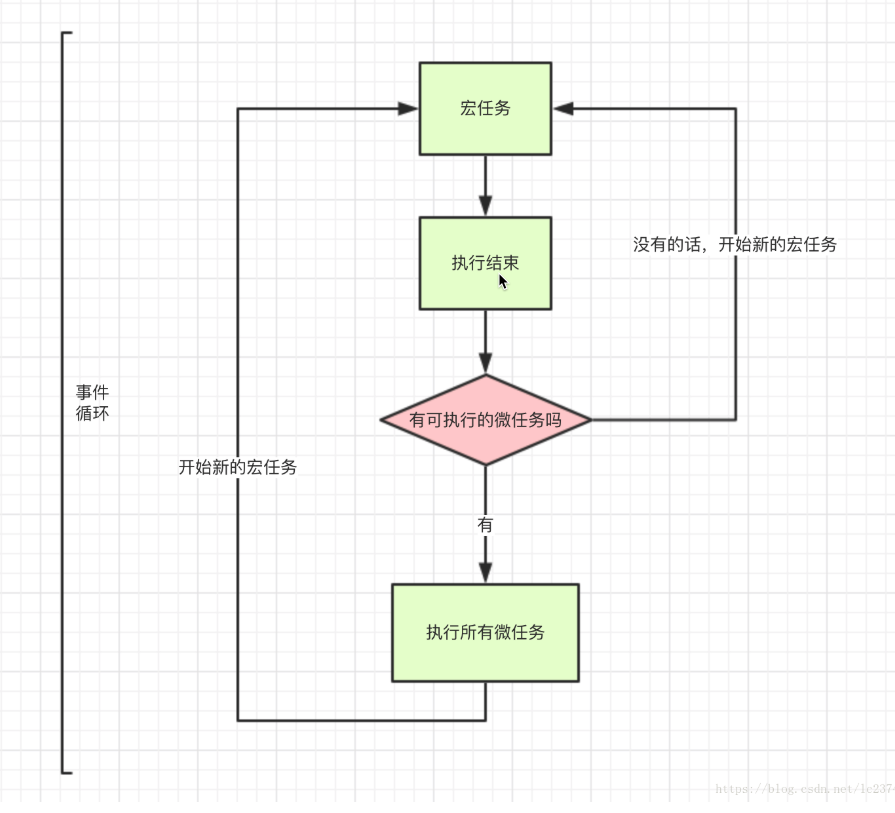
setTimeout(() => { |
高频面试题
setTimeout(() => { |
每轮事件循环执行一个宏任务和所有的微任务。
setTimeout(() => { |
任务队列一定会保持先进先出的顺序执行。
第三章 nodejs事件循环
当Node.js启动时会初始化event loop, 每一个event loop都会包含按如下六个循环阶段,nodejs事件循环和浏览器的事件循环完全不一样。
When Node.js starts, it initializes the event loop, processes the provided input script (or drops into the REPL, which is not covered in this document) which may make async API calls, schedule timers, or call process.nextTick(), then begins processing the event loop.
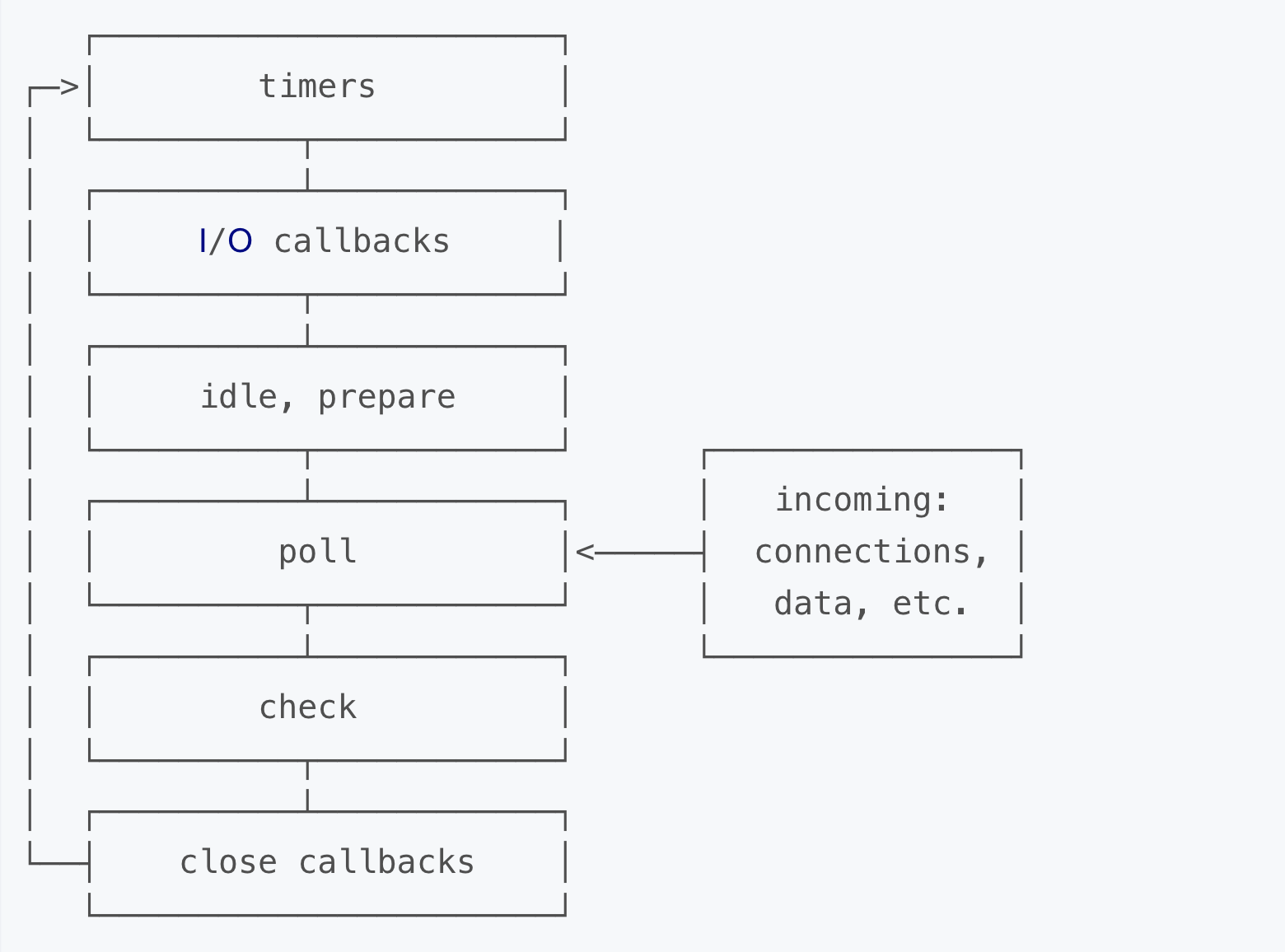
注意: 图中的每个方框被称作事件循环的一个”阶段(phase)”, 这6个阶段为一轮事件循环。
阶段概览
timers(定时器) : 此阶段执行那些由
setTimeout()和setInterval()调度的回调函数.I/O callbacks(I/O回调) : 此阶段会执行几乎所有的回调函数, 除了 close callbacks(关闭回调) 和 那些由 timers 与
setImmediate()调度的回调.setImmediate 约等于 setTimeout(cb,0)
idle(空转), prepare : 此阶段只在内部使用
poll(轮询) : 检索新的I/O事件; 在恰当的时候Node会阻塞在这个阶段
check(检查) :
setImmediate()设置的回调会在此阶段被调用close callbacks(关闭事件的回调): 诸如
socket.on('close', ...)此类的回调在此阶段被调用
在事件循环的每次运行之间, Node.js会检查它是否在等待异步I/O或定时器, 如果没有的话就会自动关闭.
如果event loop进入了 poll阶段,且代码未设定timer,将会发生下面情况:
- 如果poll queue不为空,event loop将同步的执行queue里的callback,直至queue为空,或执行的callback到达系统上限;
- 如果poll queue为空,将会发生下面情况:
- 如果代码已经被setImmediate()设定了callback, event loop将结束poll阶段进入check阶段,并执行check阶段的queue (check阶段的queue是 setImmediate设定的)
- 如果代码没有设定setImmediate(callback),event loop将阻塞在该阶段等待callbacks加入poll queue,一旦到达就立即执行
如果event loop进入了 poll阶段,且代码设定了timer:
- 如果poll queue进入空状态时(即poll 阶段为空闲状态),event loop将检查timers,如果有1个或多个timers时间时间已经到达,event loop将按循环顺序进入 timers 阶段,并执行timer queue.
代码执行1
path.resolve()方法会把一个路径或路径片段的序列解析为一个绝对路径。
fs.readFile异步地读取文件的全部内容。
__dirname总是指向被执行文件夹的绝对路径
var fs = require('fs'); |
代码执行2
var fs = require('fs'); |
代码执行3
在nodejs中, setTimeout(demo, 0) === setTimeout(demo, 1)
在浏览器里面 setTimeout(demo, 0) === setTimeout(demo, 4)
setTimeout(function timeout () { |
因为event loop的启动也是需要时间的,可能执行到poll阶段已经超过了1ms,此时setTimeout会先执行。反之setImmediate先执行
var path = require('path'); |
process.nextTick
process.nextTick()不在event loop的任何阶段执行,而是在各个阶段切换的中间执行,即从一个阶段切换到下个阶段前执行。
var fs = require('fs'); |
设计原因
允许开发者通过递归调用 process.nextTick() 来阻塞I/O操作。
nextTick应用场景
- 在多个事件里交叉执行CPU运算密集型的任务:
var http = require('http'); |
在这种模式下,我们不需要递归的调用compute(),我们只需要在事件循环中使用process.nextTick()定义compute()在下一个时间点执行即可。在这个过程中,如果有新的http请求进来,事件循环机制会先处理新的请求,然后再调用compute()。反之,如果你把compute()放在一个递归调用里,那系统就会一直阻塞在compute()里,无法处理新的http请求了。
- 保持回调函数异步执行的原则
当你给一个函数定义一个回调函数时,你要确保这个回调是被异步执行的。下面我们看一个例子,例子中的回调违反了这一原则:
function asyncFake(data, callback) { |
为什么这样不好呢?我们来看Node.js 文档里一段代码:
var client = net.connect(8124, function() { |
在上面的代码里,如果因为某种原因,net.connect()变成同步执行的了,回调函数就会被立刻执行,因此回调函数写到客户端的变量就永远不会被初始化了。
这种情况下我们就可以使用process.nextTick()把上面asyncFake()改成异步执行的:
function asyncReal(data, callback) { |
用在事件触发过程中
EventEmitter有2个比较核心的方法, on和emit。node自带发布/订阅模式
var EventEmitter = require('events').EventEmitter; |
var stream = new StreamLibrary('fooResource'); |
function StreamLibrary(resourceName) { |
第四章 nodejs多进程
本章概要
- 为什么要使用多进程
- 多进程和多线程介绍
- nodejs开启多线程和多进程的方法
- cluster原理介绍
为什么需要多进程
- nodejs单线程,在处理http请求的时候一个错误都会导致整个进程的退出,这是灾难级的。
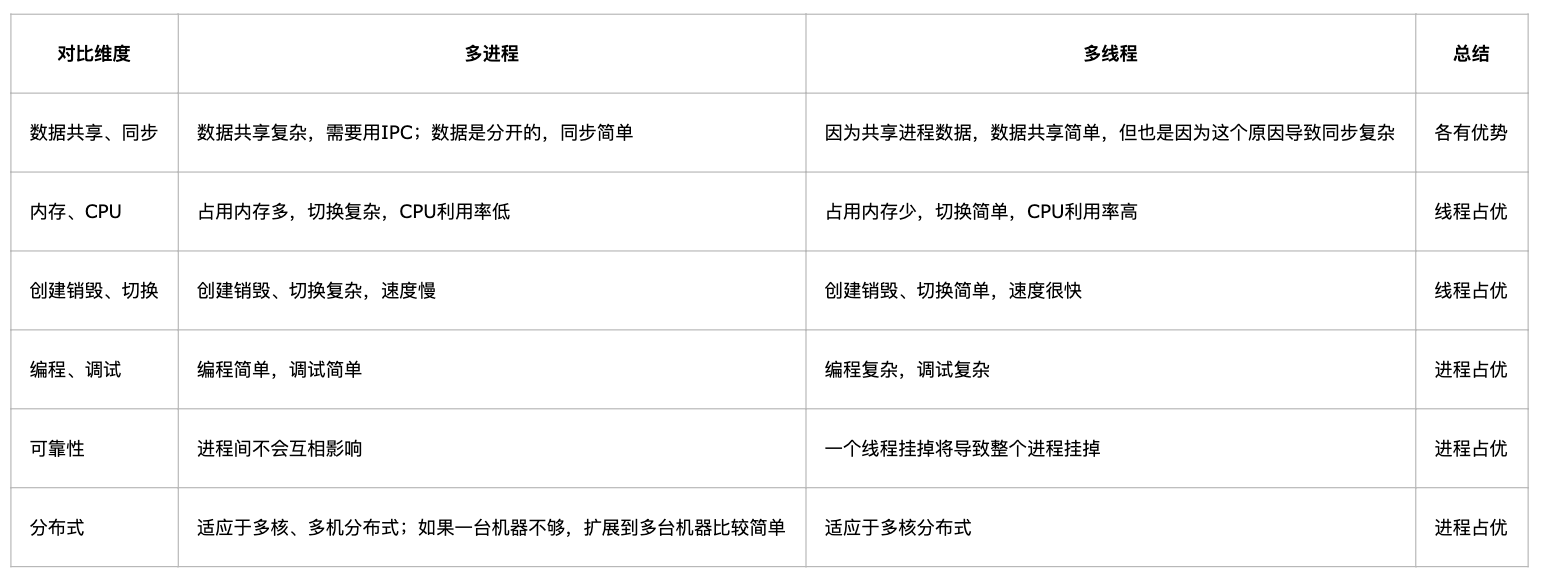
多进程和多线程介绍
进程是资源分配的最小单位,线程是CPU调度的最小单位
“进程——资源分配的最小单位,线程——程序执行的最小单位”
线程是进程的一个执行流,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。一个进程由几个线程组成,线程与同属一个进程的其他的线程共享进程所拥有的全部资源。
一个进程下面的线程是可以去通信的,共享资源
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程没有单独的地址空间,一个线程死掉就等于整个进程死掉。
谷歌浏览器
- 进程: 一个tab就是一个进程
- 线程: 一个tab又由多个线程组成,渲染线程,js执行线程,垃圾回收,service worker 等等
node服务
ab是apache自带的压力测试工具。
ab -n1000 -c20 '192.168.31.25:8000/'- 进程:监听某一个端口的http服务
- 线程: http服务由多个线程组成,比如:
- 主线程:获取代码、编译执行
- 编译线程:主线程执行的时候,可以优化代码
- Profiler线程:记录哪些方法耗时,为优化提供支持
- 其他线程:用于垃圾回收清除工作,因为是多个线程,所以可以并行清除
到底选择多进程还是多线程?
多进程还是多线程一般是结合起来使用,千万不要陷入一种非此即彼的误区。
1)需要频繁创建销毁的优先用线程
这种原则最常见的应用就是Web服务器了,来一个连接建立一个线程,断了就销毁线程,要是用进程,创建和销毁的代价是很难承受的
2)需要进行大量计算的优先使用线程
所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。
这种原则最常见的是图像处理、算法处理。
3)强相关的处理用线程,弱相关的处理用进程
什么叫强相关、弱相关?理论上很难定义,给个简单的例子就明白了。
一般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。
4)可能要扩展到多机分布的用进程,多核分布的用线程
5)都满足需求的情况下,用你最熟悉、最拿手的方式
总结: 线程快而进程可靠性高。
nodejs多线程
伴随10.5.0的发布,Node.js 新增了对多线程的实验性支持(worker_threads模块)。2018年
nodejs主流还是只有多进程的方案,多线程可以等api稳定之后再使用。
创建多进程
利用cluster开启多进程
var cluster = require('cluster'); |
稍微优化下:
var cluster = require('cluster'); |
多进程和单进程性能对比
多进程的性能要明显好于单进程
ab是apache自带的压力测试工具。推荐大家用mac
ab -n1000 -c20 '192.168.31.25:8000/'
- n 请求数量
- c 并发数
nodejs调试方法
https://code.visualstudio.com/Docs/editor/debugging
vscode的 .vscode文件下面配置 launch.json
{ |
cluster相关API
Process 进程 、child_process 子进程 、Cluster 集群
process进程
process 对象是 Node 的一个全局对象,提供当前 Node 进程的信息,他可以在脚本的任意位置使用,不必通过 require 命令加载。
属性
- process.argv 属性,返回一个数组,包含了启动 node 进程时的命令行参数
- process.env 返回包含用户环境信息的对象,可以在 脚本中对这个对象进行增删改查的操作
- process.pid 返回当前进程的进程号
- process.platform 返回当前的操作系统
- process.version 返回当前 node 版本
方法
- process.cwd() 返回 node.js 进程当前工作目录
- process.chdir() 变更 node.js 进程的工作目录
- process.nextTick(fn) 将任务放到当前事件循环的尾部,添加到 ‘next tick’ 队列,一旦当前事件轮询队列的任务全部完成,在 next tick 队列中的所有 callback 会被依次调用
- process.exit() 退出当前进程,很多时候是不需要的
- process.kill(pid[,signal]) 给指定进程发送信号,包括但不限于结束进程
事件
beforeExit 事件,在 Node 清空了 EventLoop 之后,再没有任何待处理任务时触发,可以在这里再部署一些任务,使得 Node 进程不退出,显示的终止程序时(process.exit()),不会触发
exit 事件,当前进程退出时触发,回调函数中只允许同步操作,因为执行完回调后,进程金辉退出
uncaughtException 事件,当前进程抛出一个没有捕获的错误时触发,可以用它在进程结束前进行一些已分配资源的同步清理操作,尝试用它来恢复应用的正常运行的操作是不安全的
重点关注
warning 事件,任何 Node.js 发出的进程警告,都会触发此事件
child_process
nodejs中用于创建子进程的模块,node中大名鼎鼎的cluster是基于它来封装的。
- exec()
异步衍生出一个 shell,然后在 shell 中执行命令,且缓冲任何产生的输出,运行结束后调用回调函数
var exec = require('child_process').exec; |
由于标准输出和标准错误都是流对象(stream),可以监听data事件,因此上面的代码也可以写成下面这样。
var exec = require('child_process').exec; |
上面的代码还有一个好处。监听data事件以后,可以实时输出结果,否则只有等到子进程结束,才会输出结果。所以,如果子进程运行时间较长,或者是持续运行,第二种写法更好。
- execSync()
exec()的同步版本
- execFile()
execFile方法直接执行特定的程序shell,参数作为数组传入,不会被bash解释,因此具有较高的安全性。
const {execFile} = require('child_process'); |
- spawn()
spawn方法创建一个子进程来执行特定命令shell,用法与execFile方法类似,但是没有回调函数,只能通过监听事件,来获取运行结果。它属于异步执行,适用于子进程长时间运行的情况。
const { spawn } = require('child_process'); |
spawn返回的结果是Buffer需要转换为utf8
- fork()
fork方法直接创建一个子进程,执行Node脚本,fork('./child.js') 相当于 spawn('node', ['./child.js']) 。与spawn方法不同的是,fork会在父进程与子进程之间,建立一个通信管道pipe,用于进程之间的通信,也是IPC通信的基础。
main.js
var child_process = require('child_process'); |
child.js
process.on('message', function (m) { |
cluster
node进行多进程的模块
属性和方法
- isMaster 属性,返回该进程是不是主进程
- isWorker 属性,返回该进程是不是工作进程
- fork() 方法,只能通过主进程调用,衍生出一个新的 worker 进程,返回一个 worker 对象。和process.child的区别,不用创建一个新的child.js
- setupMaster([settings]) 方法,用于修改 fork() 默认行为,一旦调用,将会按照cluster.settings进行设置。
- settings 属性,用于配置,参数 exec: worker文件路径;args: 传递给 worker 的参数;execArgv: 传递给 Node.js 可执行文件的参数列表
事件
- fork 事件,当新的工作进程被 fork 时触发,可以用来记录工作进程活动
- listening 事件,当一个工作进程调用 listen() 后触发,事件处理器两个参数 worker:工作进程对象
- message事件, 比较特殊需要去在单独的worker上监听。
- online 事件,复制好一个工作进程后,工作进程主动发送一条 online 消息给主进程,主进程收到消息后触发,回调参数 worker 对象
- disconnect 事件,主进程和工作进程之间 IPC 通道断开后触发
- exit 事件,有工作进程退出时触发,回调参数 worker 对象、code 退出码、signal 进程被 kill 时的信号
- setup 事件,cluster.setupMaster() 执行后触发
文档地址:
https://nodejs.org/api/child_process.html 多看文档!
cluster多进程模型
每个worker进程通过使用child_process.fork()函数,基于IPC(Inter-Process Communication,进程间通信),实现与master进程间通信。
那我们直接用child_process.fork()自己实现不就行了,干嘛需要cluster呢?
这样的方式仅仅实现了多进程。多进程运行还涉及父子进程通信,子进程管理,以及负载均衡等问题,这些特性cluster帮你实现了。 |
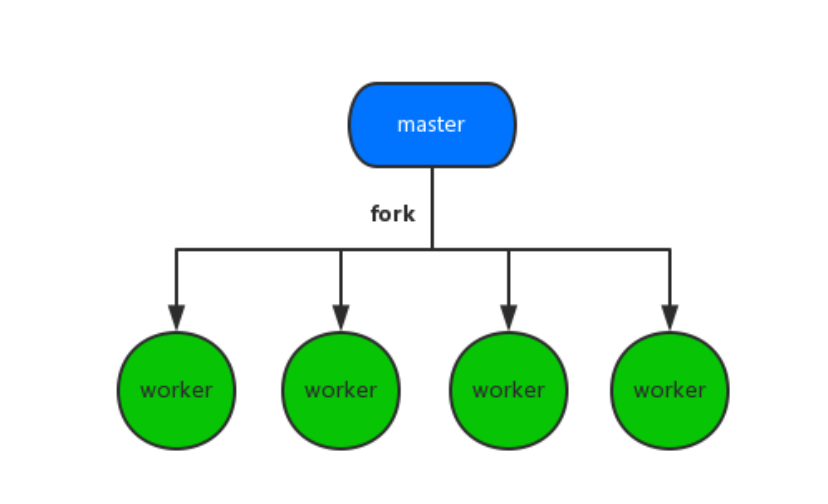
最初的多进程模型
最初的 Node.js 多进程模型就是这样实现的,master 进程创建 socket,绑定到某个地址以及端口后,自身不调用 listen 来监听连接以及 accept 连接,而是将该 socket 的 fd 传递到 fork 出来的 worker 进程,worker 接收到 fd 后再调用 listen,accept 新的连接。但实际一个新到来的连接最终只能被某一个 worker 进程 accpet 再做处理,至于是哪个 worker 能够 accept 到,开发者完全无法预知以及干预。这势必就导致了当一个新连接到来时,多个 worker 进程会产生竞争,最终由胜出的 worker 获取连接。
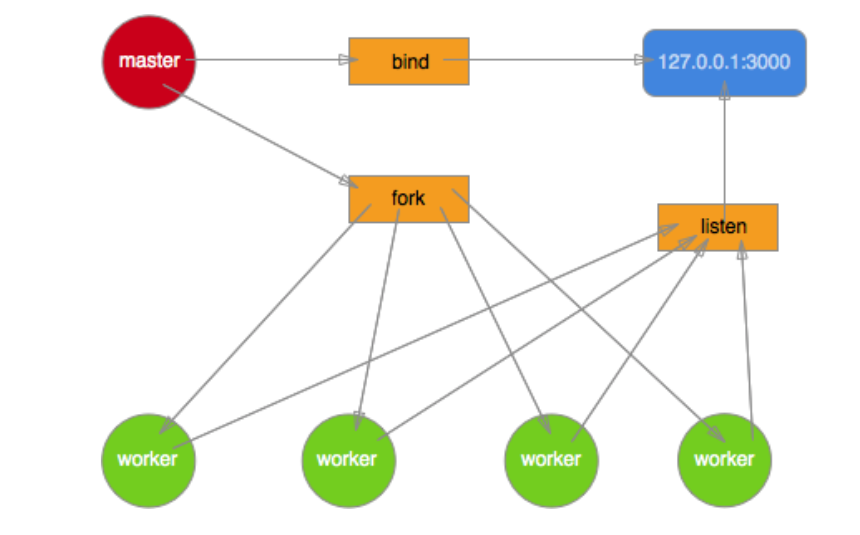
相信到这里大家也应该知道这种多进程模型比较明显的问题了
- 多个进程之间会竞争 accpet 一个连接,产生惊群现象,效率比较低。
- 由于无法控制一个新的连接由哪个进程来处理,必然导致各 worker 进程之间的负载非常不均衡。
这其实就是著名的”惊群”现象。
简单说来,多线程/多进程等待同一个 socket 事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。
惊群通常发生在 server 上,当父进程绑定一个端口监听 socket,然后 fork 出多个子进程,子进程们开始循环处理(比如 accept)这个 socket。每当用户发起一个 TCP 连接时,多个子进程同时被唤醒,然后其中一个子进程 accept 新连接成功,余者皆失败,重新休眠。
http.Server继承了net.Server, http客户端与http服务端的通信均依赖于socket(net.Socket)。
const net = require('net'); |
const net = require('net'); |

nginx proxy
Nginx 是俄罗斯人编写的十分轻量级的 HTTP 服务器,Nginx,它的发音为“engine X”,是一个高性能的HTTP和反向代理服务器。异步非阻塞I/O,而且能够高并发。
正向代理: 客户端为代理,服务器不知道客户端是谁。
反向代理: 服务器为代理,客户端不知道服务器是谁。
nginx配置demo:
http { |
nginx的实际应用场景:比较适合稳定的服务
- 静态资源服务器: js, css, html
- 企业级集群
守护进程: 退出命令行窗口之后,服务一直处于运行状态
cluster多进程调度模型
cluster是由master监听请求,再通过round-robin算法分发给各个worker,避免了惊群现象的发生。
round-robin 轮询调度算法的原理是每一次把来自用户的请求轮流分配给内部中的服务器
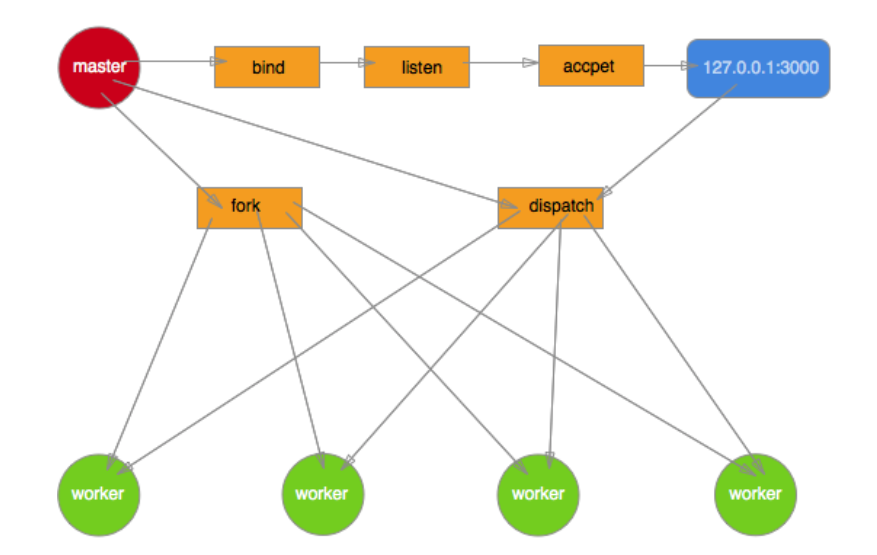
cluster调度模型简易demo
master.js
const net = require('net'); |
const net = require('net'); |
cluster中的优雅退出
- 关闭异常 Worker 进程所有的 TCP Server(将已有的连接快速断开,且不再接收新的连接),断开和 Master 的 IPC 通道,不再接受新的用户请求。
- Master 立刻 fork 一个新的 Worker 进程,保证在线的『工人』总数不变。
- 异常 Worker 等待一段时间,处理完已经接受的请求后退出。
if (cluster.isMaster) { |
进程守护
master 进程除了负责接收新的连接,分发给各 worker 进程处理之外,还得像天使一样默默地守护着这些 worker 进程,保障整个应用的稳定性。一旦某个 worker 进程异常退出就 fork 一个新的子进程顶替上去。
这一切 cluster 模块都已经好处理了,当某个 worker 进程发生异常退出或者与 master 进程失去联系(disconnected)时,master 进程都会收到相应的事件通知。
cluster.on('exit', function () { |
IPC通信
IPC通信就是进程间的通信。
虽然每个 Worker 进程是相对独立的,但是它们之间始终还是需要通讯的,叫进程间通讯(IPC)。下面是 Node.js 官方提供的一段示例代码
; |
细心的你可能已经发现 cluster 的 IPC 通道只存在于 Master 和 Worker 之间,Worker 与 Worker 进程互相间是没有的。那么 Worker 之间想通讯该怎么办呢?通过 Master 来转发。
核心: worker直接的通信,靠master转发,利用workder的pid。
 微信
微信 支付宝
支付宝





